LinkedIn
LinkedIn
 Twitter
Twitter
 Facebook
Facebook
 Youtube
Youtube




Nobody decides to build a custom TMS for fun. It starts when SaaS stops paying its way: per-truck pricing that outgrew the value it returns, ERP and WMS integrations that cost more than the platform license, or a dispatch rule so specific that every vendor demo ends with “you’d handle that part manually.”
If you’re past that point and into scoping how to build a custom TMS, this is for you. It assumes you already know what a TMS does; if not, What Is a Transportation Management System and How Does It Work covers that first.
Why Companies Build a Custom TMS Instead of Buying SaaS
The transportation management system market was estimated at $18.56 billion in 2025 and is projected to grow at a 17.8% CAGR through 2033, according to Grand View Research. Most of that spend goes to SaaS, and for operations that fit a vendor’s profile, SaaS is the right call. The companies that move to a custom build are the ones where the fit breaks down on one of five fronts.
- Billing economics. Per-truck or per-shipment SaaS pricing scales linearly with the fleet. Past a certain volume the subscription becomes a large recurring line item that doesn’t buy proportionally more capability, and the three-to-five-year total cost of ownership for a custom platform starts to look lower.
- Workflow fit. Non-standard tariff models, multi-modal operations, and industry-specific compliance rarely come out of the box. The team ends up running the unsupported part of the workflow on a spreadsheet beside the TMS.
- Integration overhead. Deep two-way integration with a corporate ERP, a legacy WMS, and telematics through a SaaS product often needs paid middleware, and a vendor update can break those connections without warning.
- Roadmap control. The SaaS vendor sets the order of the next release. A company that needs a specific capability either waits for it or pays for enterprise customization to jump the queue.
- IP ownership. A custom TMS is an asset on the balance sheet with a valuation at M&A or IPO, not a subscription expense. Several companies build precisely because the platform encodes a competitive advantage they don’t want to rent. Owning the platform also makes the company look stronger to investors and buyers.
SaaS is the wrong choice only for a specific operation whose freight complexity, integration depth, or scale has outgrown what a configurable product can hold.
Three Approaches to Custom TMS Development
How much to build from zero is the decision that sets the budget and the timeline, and most teams get it wrong by defaulting to an extreme. There are three paths.
Build from scratch
Every module written to your requirements, starting from an empty repository. Maximum control over architecture and data model, the highest initial cost, and the longest time to a first working version. This is the right call only when the operational logic is unusual enough that no existing framework can even serve as a starting point. It’s a rare situation, and an expensive one to be wrong about.
Build on a logistics framework
Development on top of a ready modular base such as the TwinCore Logistics Framework or a comparable architecture. The commodity pieces (order management, the rate engine, shipment tracking, dispatch) already exist, so the team spends its time on the custom business logic that actually distinguishes the operation. For most logistics companies this is the balance point between speed and control, and it cuts time to a working MVP by roughly a third without giving up flexibility where it matters.
Phased SaaS-to-custom migration
Start on SaaS for the basic processes, build custom modules for the specific needs in parallel, and migrate gradually. This lowers risk and lets the team test assumptions before a large commitment. It needs a clear migration plan, because running two systems side by side for longer than planned carries its own operational cost.
Core TMS Modules: What to Build First and What to Defer
A full TMS module map is a long list, and Typical Structure of a TMS walks through every module and how they connect. When building a TMS, the question is narrower: not what exists, but what has to ship in version one and what can wait. Sequencing wrong here is the most common way a custom TMS budget overruns: teams build a control tower before the rate engine is stable.
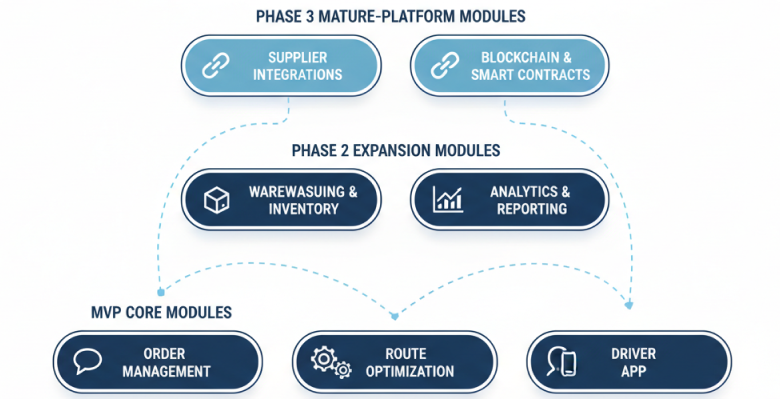
MVP core: the modules the system can’t run without
- Order management: order intake, status model, the base business logic. Every other module reads from this record, so it goes first.
- Rate engine: comparison of carrier rates and contract rates, plus custom tariff logic. This is usually the hardest module by business logic: rate zones, accessorial charges, and the calculations specific to how your contracts actually work.
- Carrier management: onboarding, credentials, service lanes, performance history.
- Dispatch and load tendering: assigning shipments to carriers, the tender workflow, confirmation tracking.
- Shipment tracking: real-time status from the carrier or from telematics, ETA calculation, delivery confirmation.
- Basic reporting: freight spend, on-time rate, carrier performance, enough to run the operation day to day.
Phase 2: added once the MVP is stable
- Route optimization: AI-driven sequencing, dynamic rerouting, capacity constraints.
- Load consolidation and load building: grouping orders into the cheapest workable loads, LTL into FTL, multi-stop routes. This is a separate job from route optimization, which sequences a load that already exists; this module decides what goes on the truck in the first place, and it cuts freight spend directly.
- Document management (BOL, POD, customs docs): capture and storage of transport documents, OCR on proof-of-delivery, each document tied to its shipment record. The work most teams run on email and shared drives until it stops scaling.
- Freight audit and invoice reconciliation: automatic matching of carrier invoices against the planned rate. This one pays for itself: freight payment processors that audit at volume, Cass Information Systems among the largest in North America, report billing discrepancies running 3–8% of total freight spend for operations without systematic audit.
- Customer portal: self-service tracking, ETA notifications, document access.
- Driver mobile app: only if there’s an owned fleet or a need for direct driver communication.
- Analytics and BI layer: carrier scorecards, cost allocation by client or cost center.
Phase 3: for a mature platform
- Control tower: aggregated visibility across all operations, exception management, predictive alerts.
- AI and ML modules: demand forecasting, predictive ETA, anomaly detection in freight audit, dynamic pricing.
- Multi-modal and international: cross-border compliance, customs documentation, multimodal shipment management.
Building these as separate, well-bounded modules rather than one tangled codebase is what keeps Phase 2 and Phase 3 affordable. A modular architecture lets you add the freight audit module without reopening the rate engine, which is the difference between a six-week addition and a six-month one.
Technical Architecture for a Custom Transportation Management System
- Backend. .NET or Node.js, both mature for enterprise logistics with deep talent pools. Pick microservices or a modular monolith by team size and load, not fashion: the monolith starts simpler and splits into services when load demands it. Event-driven patterns carry the real-time side: tracking events, dispatch notifications, ETA updates. TwinCore builds this layer on .NET.
- Database. Relational (PostgreSQL, SQL Server) for transactional data: orders, shipments, invoices. A time-series or document store for tracking and sensor data. The rate-engine and billing schema is the hardest part to model, so get it right at the start; refactoring a rate model after a year of live data is one of the worst jobs in this domain.
- Integration layer. EDI 204/210/214 for US carriers, maintained by ASC X12. REST APIs for modern carriers and 3PLs. Webhooks or event streaming for live tracking feeds. An API gateway in front of ERP, WMS, and customer-portal integrations.
- Frontend. React or Angular for the dispatcher dashboard and admin UI. React Native or native iOS/Android for the driver app, depending on offline and hardware needs.
- Infrastructure. Azure or AWS, container-based, CI/CD from day one. A system that ships constant carrier and rate updates needs a reliable deploy process before its first user, not after.
Integration Architecture: What a Custom TMS Connects To
Integrations are the largest hidden cost and the main technical risk in a TMS project, and ERP integration in particular is a recurring cause of timeline slips on logistics IT projects, according to integration practitioners like DCKAP. Scoping each connection honestly at the start is what keeps the budget intact.
- ERP (SAP, Oracle, Microsoft Dynamics, NetSuite). Purpose: freight cost allocation, GL posting, vendor payments, purchase order visibility. Complexity: high. It needs two-way data flow and field mapping between two different data models, often through middleware or a custom adapter. SAP and Oracle take deeper work than NetSuite or a modern Dynamics instance with a clean API.
- WMS. Purpose: warehouse-readiness confirmation, pickup scheduling, inventory updates after delivery. Complexity: medium to high. Native integration is straightforward when the WMS exposes a modern API and painful when it doesn’t.
- Carrier systems. EDI 204 (load tender), 210 (freight invoice), 214 (shipment status) for the large US carriers; REST APIs for younger ones. A full US freight operation needs both, plus an EDI translation layer over AS2 or a VAN to handle the legacy side. Cross-border lanes add UN/EDIFACT alongside X12, so a build aimed at international freight should plan for both standards rather than assuming one.
- Freight exchanges and load boards. DAT, Truckstop, and Uber Freight for spot capacity, with their own RFQ-out, rate-and-capacity-in flow. This is a separate connection from contracted carrier systems, and it matters most for brokerage and 3PL operations that source capacity on the open market.
- Telematics, GPS, and visibility. Fleet telematics providers (Samsara, Verizon Connect, Geotab) or direct ELD integration for real-time vehicle location, and multi-carrier visibility aggregators (project44, FourKites) where status has to be normalized across carriers and modes rather than pulled from one fleet.
- Customer-facing. An OMS or e-commerce platform for order intake, and notification APIs (email, SMS) for ETA updates and delivery confirmation.
ELD and Hours-of-Service Compliance
A build that touches an owned US fleet inherits the ELD mandate. FMCSA rules require most interstate commercial drivers who keep records of duty status to run a certified electronic logging device, and the carrier has to retain that ELD data for six months.
In the build that turns into three concrete things:
- An HOS rule engine that both dispatch and the driver app respect: the 11-hour driving limit, the 14-hour on-duty window, and the 60/70-hour weekly caps, so the system never tenders a load a driver has no legal hours to run.
- ELD data ingestion from the device or telematics provider into the duty-status record, kept for the six months FMCSA requires.
- Exemption handling for short-haul drivers and the under-8-days-in-30 case, which don’t need an ELD but still need records of duty status.
Skip the rule engine and dispatch hands drivers loads they can’t legally finish, which shows up as missed deliveries, not a compliance memo.
Custom TMS Cost Breakdown
TMS development cost is one of the most-searched questions on this topic, and most answers dodge it. The numbers below reflect typical mid-market builds; the actual figure for any project is set after discovery, with a real scope attached.
| Phase | Timeline | Indicative range | What drives it |
|---|---|---|---|
| Discovery and architecture | 2–6 weeks | $10,000–$30,000 | Requirement mapping, architecture, integration scoping, data model |
| MVP, core modules | 3–6 months | $80,000–$180,000 | Rate logic complexity, number of integrations, team composition |
| Full platform, Phase 2 | +3–6 months | $60,000–$150,000 | Route optimization, freight audit, customer portal, driver app, analytics |
| ERP integration | varies | $15,000–$50,000 | ERP platform and depth of integration |
| EDI / carrier connectivity | varies | $5,000–$20,000 | Number of carriers, VAN setup |
| Telematics integration | varies | $5,000–$15,000 | Provider count and data granularity |
Discovery is the line item teams are most tempted to cut, and it’s the one that protects every figure below it.
The cost drivers that move the budget most: the complexity of the rate engine and billing logic, the number and depth of external integrations, whether there’s a driver mobile app, AI or ML components, compliance requirements (FMCSA, DOT, GDPR), and the location and seniority of the team. On the last point, the team model itself is a lever: a build led in-house with a few hired logistics software developers on the integration work prices differently from a fully outsourced delivery.
Plan for ongoing cost after launch, too: maintenance and bug fixes typically run 15–20% of the initial development cost per year, on top of cloud infrastructure and the carrier API and EDI updates that arrive whether or not you asked for them. A working rule is to budget 20–25% of the initial investment annually.
The build vs buy TMS math only resolves once a concrete scope exists.
Development Process: From Discovery to Launch
The work to build a transportation management system end to end falls into six phases.
- Discovery and scoping (2–4 weeks). Audit of current processes and systems, mapping of operational workflows, MVP scope definition, integration scoping, architecture design, and a project estimate. Output: a technical specification and a project plan.
- Architecture and design (2–3 weeks). System architecture, database schema, API design, and UI/UX wireframes for the dispatcher dashboard and the rate-entry and load-tender screens. Output: a validated architecture ready to build against.
- Iterative development (3–5 months for MVP). Sprint-based work with regular demos and feedback, backend, frontend, and integrations built in parallel, automated testing in place from the first sprint.
- Integration and testing (4–6 weeks). End-to-end testing across every integration, load testing, user acceptance testing with the operations team, and carrier onboarding with EDI testing.
- Soft launch and stabilization (2–4 weeks). A parallel run alongside the current system, monitoring, bug fixes, and operations-team training.
- Full launch and post-launch support. Handover documentation, an SLA for support, and a planned roadmap for Phase 2 modules.
How TwinCore Builds a TMS
Before writing any code, we work through the business logic of the company the TMS is for and put the architecture down on paper: the data model, module boundaries, integration seams, and the decisions below. If you skip this, the rate engine and tracking get tangled together, so any small change later means changing both.
- Multi-tenancy. Decide up front whether the platform serves one operation or many. Adding tenant isolation to a single-tenant schema after launch touches every table and every query.
- Authorization, security, and caching. Auth, roles, and data-access rules are designed at the start, not bolted on before launch. The cache provider is part of that early structure too, not a late optimization.
- Architecture shape. We start with at least a modular monolith where each module owns its database, so the boundaries are real from day one and a module can be split out later without untangling a shared schema. When the operation is high-volume from the start, we begin with microservices behind a load balancer instead. Linux hosts in both cases.
- Host independence. We write platform-independent code, so moving from Azure to AWS is a deployment change rather than a rewrite. A TMS outlives its first hosting contract, and we don’t lock the business to one provider. The exception is when the company already runs on a specific stack, Azure or AWS.
- Backend on .NET, AI on Python. .NET today is a high-quality choice for enterprise logistics: performance, tooling, and a deep talent pool. The AI components run in Python, where the libraries live, and talk to the .NET core through the integration layer.
- Data split by shape. Transactional data (orders, shipments, invoices) goes in a SQL database, PostgreSQL or SQL Server. We don’t force the core tables into a rigid static schema; the parts of the model that vary by client go dynamic, stored in MongoDB, Cosmos DB, or DynamoDB. Telemetry, GPS, and route history go to MongoDB for its time-series support.
- Routing we integrate, not write. Route optimization is a solved problem with mature APIs behind it: HERE, Google Maps Platform, and Mapbox for routing and geocoding, with PTV or Routific where heavier multi-stop optimization is needed. We connect one rather than ship a worse version of it.
- Messaging and integrations. Kafka or RabbitMQ for messaging, with the outbox pattern so a database commit and the event it emits can’t drift apart. Every external connection (ERP, carriers, telematics) lives in a separate integration layer, with resilience patterns, retries, circuit breakers, and timeouts written in explicitly rather than assumed. Operational discipline is in place from the first sprint, not added after the first incident.
- Deployments, metrics, and versioning. CI/CD runs from day one. API versioning is in place from the first endpoint. Performance monitoring (Elastic APM or Datadog) goes live the same day the system does. Performance tests are part of the build, and unit tests cover the core logic, where correctness actually matters, rather than chasing coverage everywhere.
- Real-time from the start. Dispatch, tracking, and ETA updates sit on a real-time foundation from the beginning, because retrofitting live updates onto a request-response system is a rewrite.
- Serverless where load is spiky. For uneven workloads we weigh serverless: a sudden burst of 10,000 pings spins up hundreds of instances and tears them down just as fast. The cost is an unpredictable bill, so we use it where the spikes justify it, not by default.
- AI search and analytics. On top of this we add AI-driven search and analytics over shipments, rates, and carrier performance, so the data the platform already holds becomes answerable in plain language. This runs on the TwinCore Logistics Framework, our modular base for order management, rate engine, shipment tracking, dispatch, and fleet management, which carries the commodity modules so the team’s time goes to the client’s custom logic.
Building custom TMS platforms is TwinCore’s core business, not one line in a long services list: 30+ engineers, 100+ delivered projects, working out of a Chicago office at 2315 W Chicago Ave, with a public profile on Clutch.
Conclusion
Building a custom TMS is a real investment. For companies where freight complexity, integration depth, and operational specificity have moved past what SaaS can deliver, it’s also the one that pays back. The builds that land share three things: a scope defined after discovery, a TMS architecture that treats the rate engine and integrations as the hard parts they are, and a development partner who understands freight operations as well as the code.
Ready to scope your custom TMS? Talk to TwinCore.