LinkedIn
LinkedIn
 Twitter
Twitter
 Facebook
Facebook
 Youtube
Youtube


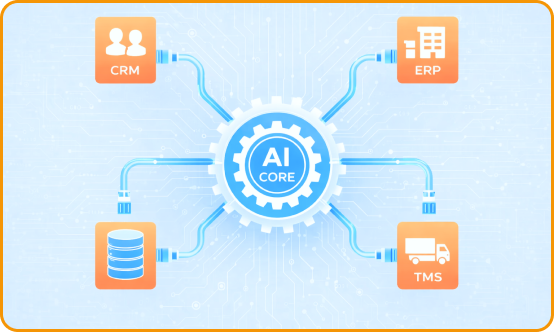
We design, build, and deploy production-grade AI agents that connect directly to your systems. These aren't passive text generators. They are active workers capable of making decisions, calling APIs, and executing complex workflows inside your CRM, ERP, or TMS.
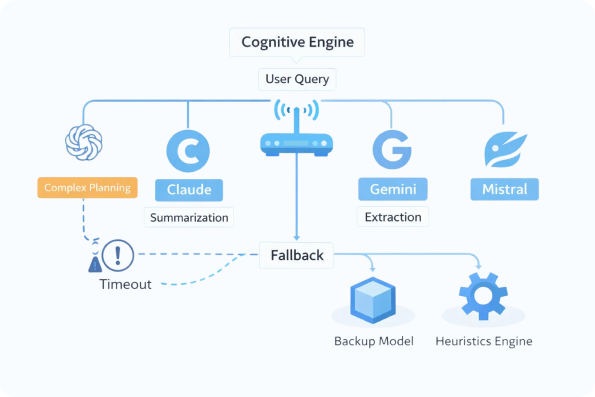
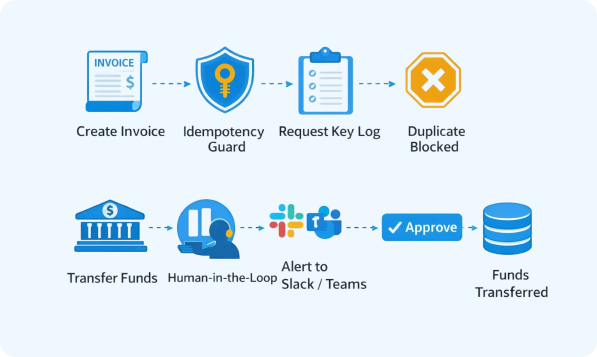
You choose the stack (C#, Python, or the Microsoft Agent Framework) and the deployment model. Then, we handle the hard engineering: memory management, tool execution, and the strict guardrails needed to keep the AI from going rogue.